A Primer on Receive-Side Scaling (RSS)
Receive-side scaling (RSS) is a technique that enables the distribution of arriving packets between multiple RX hardware queues of the network interface card (NIC) using a predefined hash function. This allows scalable processing of the received packets by 1) processing packets from different RX queues on different cores, or 2) giving CPU cores exclusive access to the NIC queues to avoid contention when accessing the NIC queues, while preserving the order of delivery of received data packets [0]. In addition, RSS reduces reloading of caches and other resources by increasing the probability that software algorithms that share data execute on the same CPU core.
The RSS Pipeline
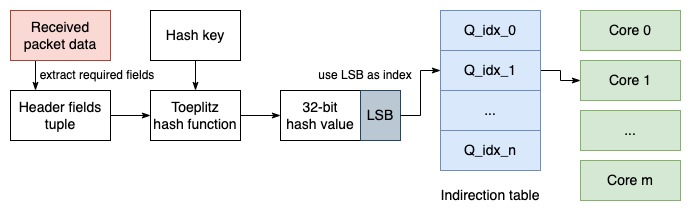
The following illustration shows the processing of packets on the NIC with regards to RSS. First, the received packet data is parsed and the required packet header fields are extracted as a tuple. This tuple is used as an input to a keyed hash function. A number of least-significant bits of resulting hash is used as an index to the indirection table. The indirection table contains entries of RX queue indices into which the corresponding packet will be inserted. Finally, the processing cores poll the queues, fetch packets and process them.
Toeplitz Hash Algorithm
In the default RSS algorithm the NIC computes the hash value based on the packet header entries using the Toeplitz hash function. The Toeplitz hash family describes hash functions that compute hash values through matrix multiplication of the hash key with a suitable Toeplitz matrix. On modern NICs the hash function is implemented in hardware. This allows for fast processing, but makes modification/updates of this function difficult. The algorithm works as follows:
function computeRSShash(input[], key)
ret = 0
for each bit b in input[]:
if b==1:
ret ^= 0xFFFFFFFF & (key >> 288) // left most 32 bits of key
key << 1
RSS can be applied to any byte ranges in the IP/TCP/UDP header, but by default uses the standard 5-tuple (src. IP, dst. IP, src. port, dst. port, protocol) to uniquely identify a TCP/UDP session. For RSS based on the 5-tuple the input size would be 12 bytes (96 bits) and the key size is 40 bytes (320 bits).
Byte Ranges for Hash Calculation
The configuration of the byte ranges used in the hash calculation can be per flow type and allows setting any combination of RSS hash byte configurations [1].
ethtool -N <dev> rx-flow-hash <type> <option>
where <type> is for example tcp4 signifying TCP over IPv4 and option is a set of hash byte configurations such as s and d for including the source and destination IP address in the hash computation [2]. The option user-def N [m N] allows the inclusion of 64-bit user-specific data and an optional mask.
Indirection Table
The indirection table can be programmed using a standard API provided by the NIC. For example, to make sure all traffic goes only to CPUs #0-#5 (of the first NUMA node), we can run:
ethtool -X <dev> weight 1 1 1 1 1 1 0 0 0 0 0
The size of the indirection table varies for each NIC model. Intel 82599 10 GbE NICs have a 128 bucket indirection table, XL710 40 GbE NICs have a 512 bucket indirection table, Mellanox ConnectX-4 and ConnectX-5 100 GbE NICs can use even more than 512 buckets. but system’s limitations restrict the table to 512 buckets in DPDK and 128 buckets in the Linux kernel driver.
Special case: Symmetric RSS
One problem with current RSS techniques that can map packets from the same TCP connection to different NIC RX queues depending on the direction of the packet. This is because the computed RSS hash of the packet differs for each direction. For example, the hash of a packet belonging to the following flow:
{src. IP=1.1.1.1, dst. IP=2.2.2.2, src. port=123, dst. port=456, prot=TCP}
differs from the reverse direction:
{src. IP=2.2.2.2, dst. IP=1.1.1.1, src. port=456, dst. port=123, prot=TCP}
Processing packets belonging to the same TCP connection on different cores might be problematic for high-performance applications that require packet processing in both direction with shared state (e.g., stateful firewalls or intrusion detection systems) because it would require sharing data structures across different threads (and potentially need locking before access).
To achieve symmetric RSS the hash key used to compute the packet hash needs to be chosen such that the hash computation results in the same hash for packets in both directions. However, changing the RSS hash key requires caution because it might lead to bad traffic distribution among the processing cores. Symmetric RSS is further discussed in the following paper [3] and suggests to use the following hash key:
# define RSS_HASH_KEY_LENGTH 40
static uint8_t hash_key[RSS_HASH_KEY_LENGTH] = {
0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A,
0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A,
0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A,
0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A, 0x6D, 0x5A,
};
For NICs using the i40e driver (e.g., XL710) symmetric RSS is already built-in and can be enabled via an API [4].
Send-side scaling
In case of send-side scaling, RSS is configured such that send and receive-side data for a given connection are processed on the same CPU. For example, a TCP application would send part of a data block and wait for an acknowledgment before sending the balance of the data. The acknowledgment then triggers subsequent send requests. The RSS indirection table identifies a particular CPU for the receive data processing. By default, the send processing runs on the same CPU if it is triggered by the receive acknowledgment [5].
Dynamic Rebalancing using RSS
Dynamic rebalacing using RSS provides means to rebalance the network processing load between processing cores dynamically as the load on cores varies. Using RSS the load can be rebalanced by updating entries in the indirection table.
RSS for IPv6
Traditional flow classification based on the 5-tuple of the source and destination addresses, ports, and the transport protocol type is not possible in case of fragmentation or encryption. Locating them past a chain of IPv6 option headers may be inefficient. This lead to the introduction of a flow label for IPv6 traffic such that IPv6 flows can be efficiently classified based on the flow lable, and the source and destionation address fields, where only IPv6 main header fields in fixed positions are used [6]. The flow label is a 20-bit field in the IPv6 header. A flow label of zero is used to indicate packets not part of any flow.
Since flows are identified by the 3-tuple of flow label, source and destination address, the tuple can be used for RSS where the input is set to the corresponding header fields in the IPv6 header.
RSS in DPDK
DPDK is a set of data-plane libraries to accelerate packet processing workloads using polling-mode drivers for offloading TCP packet processing from the operating system kernel to processes running in user space. This offloading achieves higher computing efficiency and higher packet throughput than using the interrupt-driven processing provided in the kernel.
DPDK allows for configuration of the RSS function, the hash key, and the indirection table. RSS is configured per port and the distribution depends on the number of RX queues configured on the port. By default DPDK alternatingly writes the port indices to the indirection table.
For example, for a port that is configured with 3 RX queues (0,1,2), the indirection table would be populated as follows [7]:
{0, 1, 2, 0, 1, 2, 0, ...}
Using this configuration, the traffic is distributed across the configured RX queues and the application can poll the queues using different processing cores.
To configure RSS in DPDK, it must be enabled in the port rte_eth_conf structure.
struct rte_eth_conf port_conf = {
.rxmode = {
.mq_mode = ETH_MQ_RX_RSS,
},
.rx_adv_conf = {
.rss_conf = {
.rss_key = NULL,
.rss_hf = ETH_RSS_IP
| ETH_RSS_TCP
| ETH_RSS_UDP
| ETH_RSS_SCTP
},
},
};
rte_eth_dev_configure(port_id, rx_queue_num, tx_queue_num, &port_conf);
The hash key can be configured using .rss_key (NULL for the default one).
Incoming packets in DPDK are stored in rte_mbuf structures. When RSS is enabled, the RSS hash value is stored in the associated meta data structure of the rte_mbuf and can be access with mbuf.hash.rss. This enables using the hash value in the application without recalculation.
Software-based RSS
A major advantage of RSS is the fact that it can be done in hardware. In cases where RSS is not supported by the underlying hardware or special byte ranges should be used in the hash computation, RSS can also be conducted in software. DPDK provides a Toeplitz hash library to calculate the Toeplitz hash function in software. Software-based RSS is often referred to as Receive Packet Steering (RPS) or Receive Flow Steering (RFS) [8].
Resources:
[0] https://blog.cloudflare.com/how-to-achieve-low-latency/
[1] https://www.kernel.org/doc/Documentation/networking/i40e.rst
[2] https://linux.die.net/man/8/ethtool
[3] Scalable TCP Session Monitoring with Receive Side Scaling - Woo and Park
[4] https://haryachyy.wordpress.com/2019/01/18/learning-dpdk-symmetric-rss/
[5] https://docs.microsoft.com/en-us/windows-hardware/drivers/network/introduction-to-receive-side-scaling
[6] https://datatracker.ietf.org/doc/html/rfc3697
[7] https://galsagie.github.io/2015/02/26/dpdk-tips-1/
[8] https://stackoverflow.com/questions/44958511/what-is-the-main-difference-between-rss-rps-and-rfs